Utiliziei a base de dados da FIPE referente ao mês de janeiro de 2026, para as segintes marcas: Audi, BYD, GM (Chevrolet), Citroën, Fiat, Ford, Honda, Hyundai, IVECO, JAC, Jeep, Kia Motors, Mercedes-Benz, Mitsubishi, Nissan, Peugeot, Renault, Toyota, Volkswagen, Troller e Volvo, para os modelos de carro a partir do ano de 2000.
O projeto permite analisar padrões de preços, identificar fatores determinantes e construir modelos preditivos capazes de estimar valores de veículos com base em suas características, como fabricante, modelo, ano, versão, combustível e categoria.
2. Tecnologias Utilizadas
Para garantir a robustez e escalabilidade do projeto, foram empregadas as seguintes tecnologias:
- Python – Linguagem principal para análise de dados e desenvolvimento de modelos de Machine Learning.
- Pandas e NumPy – Manipulação, limpeza e transformação de dados.
- Scikit-learn – Modelos de regressão, validação cruzada, pré-processamento e métricas de avaliação.
- Matplotlib – Visualização de dados, gráficos de dispersão e análises exploratórias.
- MLflow – Gerenciamento de experimentos, versionamento de modelos e monitoramento de métricas.
- Docker e Docker Compose – Empacotamento do projeto e orquestração de containers para ambiente de produção.
- PostgreSQL – Armazenamento estruturado de dados e resultados de experimentos.
- MinIO – Armazenamento de artifacts e modelos treinados em ambiente local ou cloud.
- Modelos Escolhidos: Árvore de decisão, random florest, SVM , Rede neural, Regressão Linear múltipla, lasso, ridge e elastic-net
- Votação: Explorarção de votting regressor
3. Etapas do Projeto
- Coleta e Pré-processamento de Dados
- Extração da base FIPE de janeiro de 2026.
- Limpeza e padronização de colunas.
- Transformação de variáveis categóricas em variáveis numéricas (one-hot encoding).
- Análise Exploratória de Dados (EDA)
- Identificação de outliers e padrões de preços por fabricante, modelo e categoria.
- Correlação entre características do veículo e preço.
- Treinamento de Modelos Preditivos
- Árvore de decisão, random florest, SVM , Rede neural, Regressão Linear múltipla, lasso, ridge e elastic-net
- Otimização de hiperparâmetros via Grid Search.
- Validação e Avaliação
- Métricas: MAE, RMSE e R².
- Comparação de desempenho entre modelos e escolha do melhor modelo para produção, usando testes estátisticos.
- Implementação em Produção
- Containerização com Docker e Docker Compose.
- Armazenamento de modelos e resultados com MLflow e MinIO.
- API de previsão para consulta de preços baseada nas características do veículo.
4. Resultados e Discussão
4.1 Análise Exploratória de Dados (EDA)
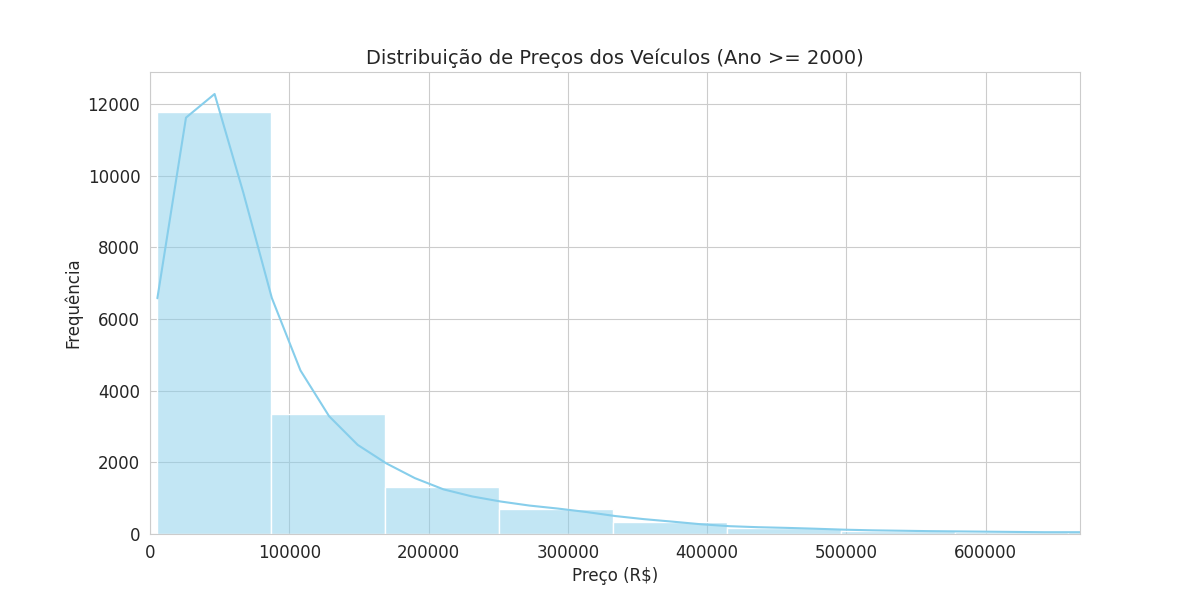
A figura acima mostra a distribuição de preços do carro. Ela mosta que a grande maioria de carros, variam de R$30 mil a R$ 150 mil, indicqando carros populares, puxando a calda mais a equerda, para regressores lineares, podem ter dificuldade com essa assimétria.
4.2 – Análise overfiting – underfiting

A figura acima mostra o desempenho overfiting e underfiting, com base nas diferenças do rmse treino e teste, o modelo consegue generalizar para os dados novos.
4.3 Desempenho dos Modelos Preditivos
A tabela abaixo mostra os melhores resultados após o tuning de parâmetros:
| Modelo |
MAE (R$) |
RMSE (R$) |
R² |
| 🟢 Random Forest |
13267.8307 |
25994.6953 |
0.9082 |
| 🔵 Rede Neural |
14920.0846 |
27964.7417 |
0.8938 |
| Árvore de Decisão |
14259.9215 |
28439.9057 |
0.8901 |
| Lasso |
29395.8449 |
43092.7437 |
0.7478 |
| Ridge |
29402.1193 |
43093.5964 |
0.7478 |
| Elastic-Net |
29710.2578 |
43301.6977 |
0.7453 |
| Regressão Linear |
1856916601.7858 |
43091.9552 |
0.7478 |
| SVM |
29990.3667 |
61941.6692 |
0.4789 |
Observações Importantes
-
Modelos baseados em ensembles (Random Forest e Rede Neural) apresentaram melhor desempenho, demonstrando maior capacidade de capturar a variabilidade de preços entre diferentes categorias e fabricantes.
-
Modelos lineares (Regressão Linear, Lasso, Ridge e Elastic-Net) mostraram limitações ao lidar com não-linearidades e interações complexas presentes nos dados. Ainda assim, serviram como baseline confiável para comparação de desempenho.
4.4 – Análise da Importância dos Atributos
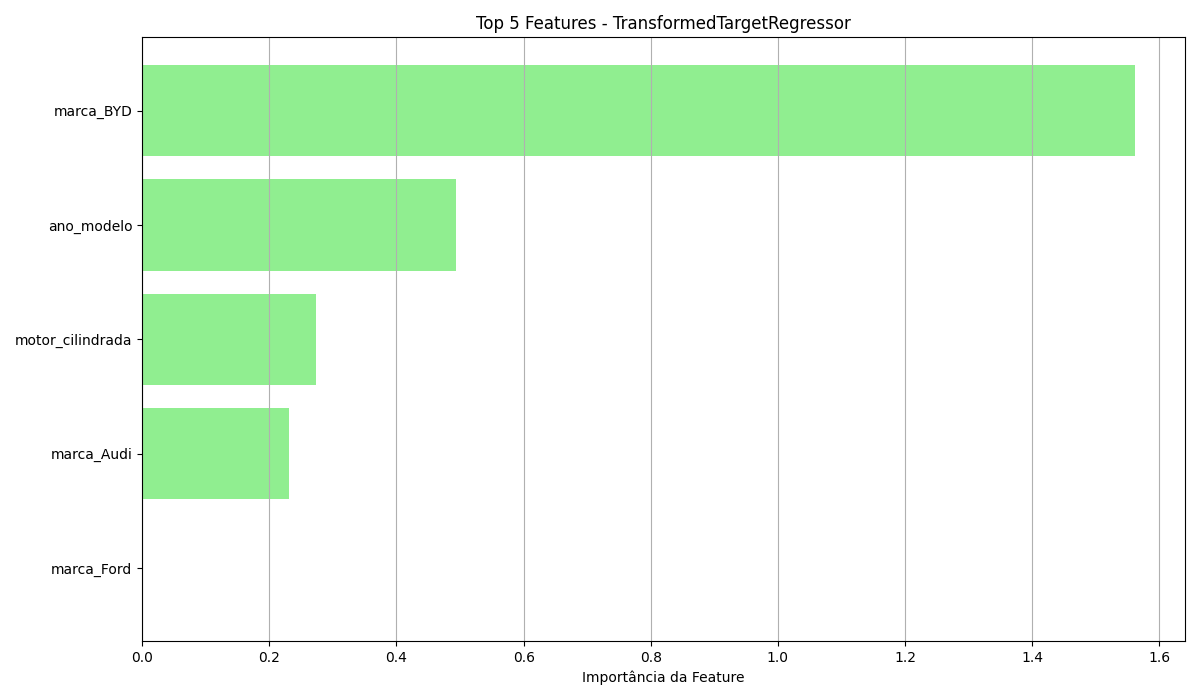

As figuras acimas mostram as importancias das caracteristicas para random florest e rede neural. Os gráficos revalo para o atributo ano modelo do random forest, este apresenta 50% da importância , mostrando que a drepeciação temporal é um fator decisivo para o modelo.
Para as marcas, o BYD, tem uma importancia significativa na rede neural enquanto as marcas Mercedes Bens e Audi, tem pouca presença.
4.5 Escolha do modelo (Teste de Fiedman e Nemenyi)
O teste de Friedman é um teste não paramétrico para medidas repetidas, usado para comparar três ou mais grupos relacionados, mas não pode assumir normalidade.
O teste de Nemenyi é um teste pós-hoc não paramétrico, usado após o teste de Friedman para comparar pares de grupos e identificar quais tratamentos diferem.
``
O gráfico abaixo representa o resultado final para a escolha do modelo. Com base no modelo, random florest e rede neural são estátiticamente iguais, mas diferêntes das quatro regressões lineares. Regressão svr (SVM), teve o pior desempenho entre os modelos.

4.6 Demonstração em Produção
• O modelo final foi containerizado com Docker, permitindo fácil implantação em qualquer ambiente.
• MLflow gerencia o versionamento do modelo e métricas, garantindo rastreabilidade e reprodutibilidade.
• MinIO armazena os artifacts do modelo, garantindo acesso seguro e escalável.
• A API de previsão pode fornecer estimativas de preços em tempo real para usuários finais ou sistemas integrados, facilitando decisões de compra, venda e avaliação de veículos.